Genome Clustering¶
This interface allows the user to select a set of genomes and display a tree that groups them by genomic similarity. The tree is constructed from the pairwise distances (see Pairwise Genome Distance and ANI) between the selected genomes using a neighbor joining algorithm (see Tree Construction).
Moreover, the genomes are grouped in “species cluster” according to the pairwise distance (see Clustering Genomes). Those clusters are called MicroScope Genome Cluster (MICGC for short). The interface also displays the cluster to which the organism belong.
Note that genomes for which CheckM detected more than 5% contamination or less than 90% completeness are not assigned to MICGC clusters. Such genomes will however appear in the organism selector and are displayed in black in the tree. You can consult CheckM results in the Genome Overview page.
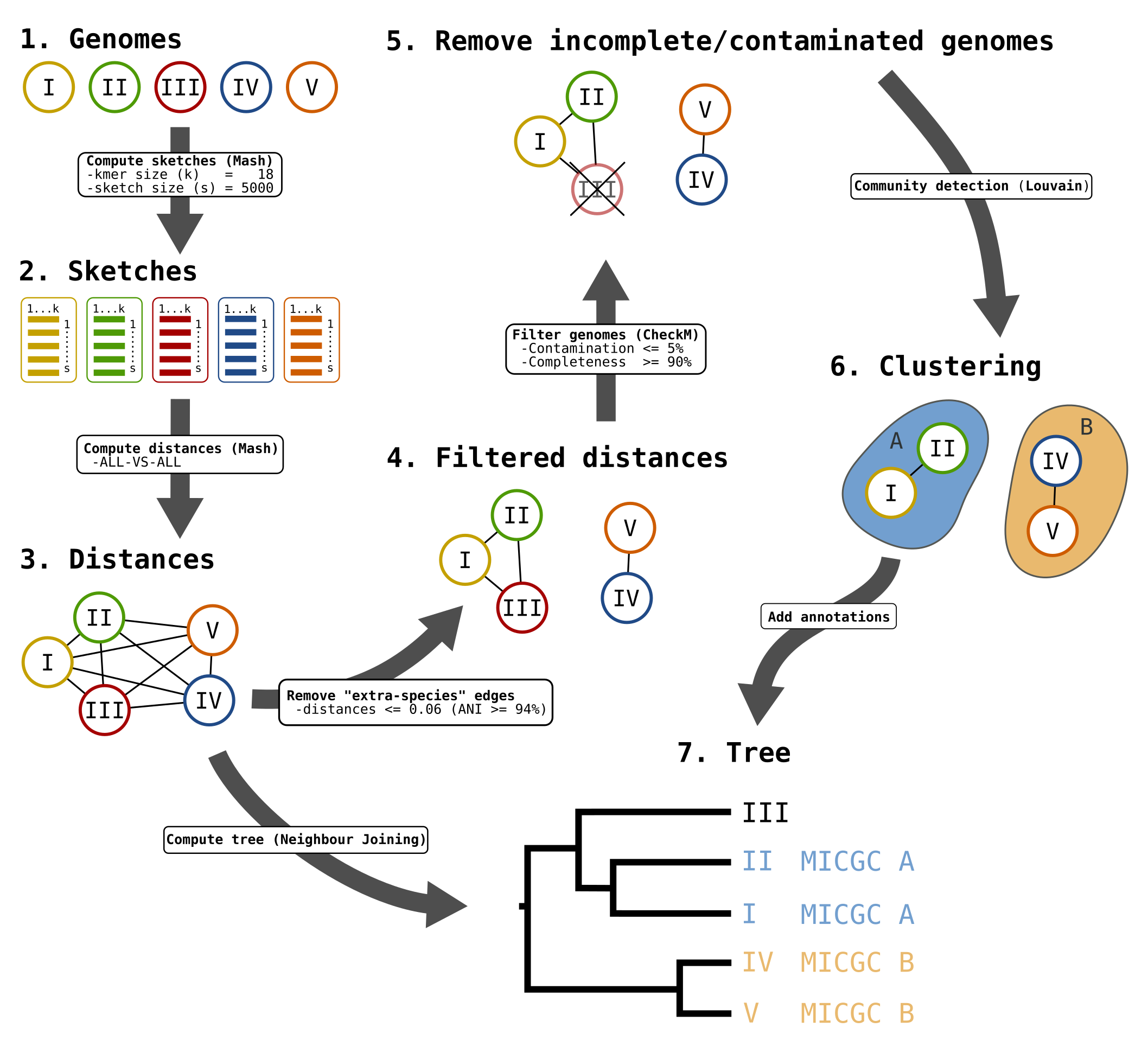
Microscope Genome Cluster (MICGC) workflow.
Interface Overview¶
Below is a screenshot of the genome selection interface.
The first part uses the advanced selector (in Genome Selection mode) to select the genomes on which the tree will be computed. See here for help on how to use this selector.
Next by clicking “Save and Run”, the tree is computed and displayed under Results.
Below is a screenshot of a tree. The user can navigate within the tree. Next to each organism, the name of the MICGC cluster is displayed. The user can click on the species cluster to get more information (in this example, the user selected the cluster MICGC13). Contaminated or incomplete genomes (not associated to MICGC clusters) are displayed in black in the tree.
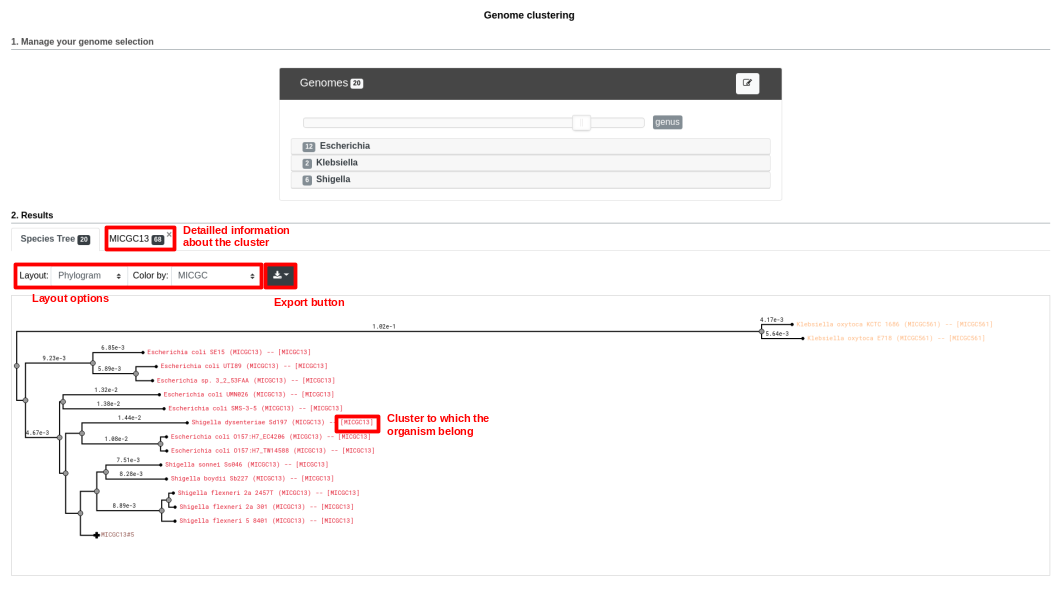
MICGC and Tree.
Pairwise Genome Distance and ANI¶
In order to quickly calculate the pairwise genome distance, we use Mash. Mash extends the MinHash dimensionality-reduction technique to include a pairwise mutation distance and a statistical significance test.
Mash distance strongly correlates with the Average Nucleotide Identity (ANI).
If 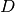 denotes the Mash distance then
denotes the Mash distance then 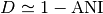 .
.
ANI represents the average nucleotide identity between homologous genomic regions shared by two genomes and offers robust resolution between strains of the same or closely related species (80-100% ANI).
It closely reflects the traditional microbiological concept of DNA-DNA hybridization relatedness for defining species (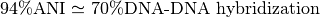 ).
).
To know now more about Mash, see here.
Reference:
Tree Construction¶
A tree is constructed from the Mash distance matrix. This tree is computed dynamically directly in the browser using a rapid neighbour joining algorithm.
This algorithm can assign a negative length to a branch. In order to avoid that and to keep the total distance between an adjacent pair of terminal nodes unchanged, we set negative branch length to zero and transfer the difference to the adjacent branch (see here for more information).
Clustering Genomes¶
Typically, two bacteria belong to the same species when 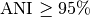 (i.e.
(i.e. 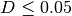 ).
).
In order to construct these species clusters, we remove the pairwise genome distances that don’t match this ANI threshold. Then we extract communities from that network.
From our tests, the best parameters to reconstruct Progenome species clusters are a threshold of 0.06 for Mash distances (i.e. 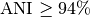 ), kmer size = 18 and sketch size = 5000.
We use those parameters.
), kmer size = 18 and sketch size = 5000.
We use those parameters.
To detect the communities, we use the louvain community detection algorithm.
Export¶
By clicking on the “Export” button:
- the tree can be exported in SVG or Newick format
- the distances can be exported in TSV format (as a matrix or as a pairwise list)
Reference: